
Sparse matrices are a special type of matrices that have a significant number of zero values. They are used in machine learning and other scientific computations due to their ability to reduce memory usage and computation time.
For example, a dense matrix of size 1000x1000 with only 10% non-zero 8-bit values would require 8 MB of memory, while its sparse equivalent would require only a 10% of that.
Apart from saving memory, sparse matrices also speed up certain operations, such as matrix multiplication, by skipping over the zero values. In fact, the performance gain can be dramatic: a sparse matrix multiplication can be up to 100x faster than its dense counterpart.
Overall, using sparse matrices can greatly improve the efficiency and scalability of machine learning algorithms, especially when dealing with zero-valued data.
Where Are Sparse Matrices Used?
Sparse representations are more used in symbolic systems like recommendation systems (item-item or item-user matrix). Or examples are adjacency matrices, word counting methods.
In area of neural networks, dense representations are the most common. For example, word2vec or FastText are dense representations (embeddings) of words. Or in case of the Transformer architecture. Even after neural network connection pruning, the activations remain rather dense.
In 2023, sparse representations also appeared in practise in the Sparse Mixture-of-Experts deep-learning architecture exemplified by widely-used Mixtral model. In each feed-forward layer of Mixtral model, only 2 of 8 (25%) get activated during inference.
Mixtral is a sparse mixture-of-experts network. It is a decoder-only model where the feedforward block picks from a set of 8 distinct groups of parameters. At every layer, for every token, a router network chooses two of these groups (the “experts”) to process the token and combine their output additively.
Dense Matrix Multiplication Example
The simplest the most common formats used.

CSR Sparse Matrix Multiplication Example
A very common sparse format that is useful in situations described in below.
Sparse Matrix Formats
Sparse matrix format compresses matrices with more than half zero values and speeds up certain operations on them. There are two main groups of the sparce matrix representations:
- efficient for incremental construction and modification DOK, LIL, COO
- efficient for access and operations CSR, CSC There are several types of sparse matrix representations, where each has an advantage in different situations.
DOK: Dictionary of Keys format:
- row, column pairs map to value,
dict((i, j): matrix[i, j] for i in matrix.shape[0] for j in matrix.shape[1])
LOL: List of Lists format:
- each row has one list of tuples of column and value
- example
[[(j, matrix[i,j]) for j in range(matrix.shape[1])] for i in range(matrix.shape[0])]
COO: COOrdinate format (aka IJV, triplet format):
- sorted list of row, column, value tuples
[(i, j, matrix[i, j]) for i in range(matrix.shape[0]) for j in range(matrix.shape[1])]
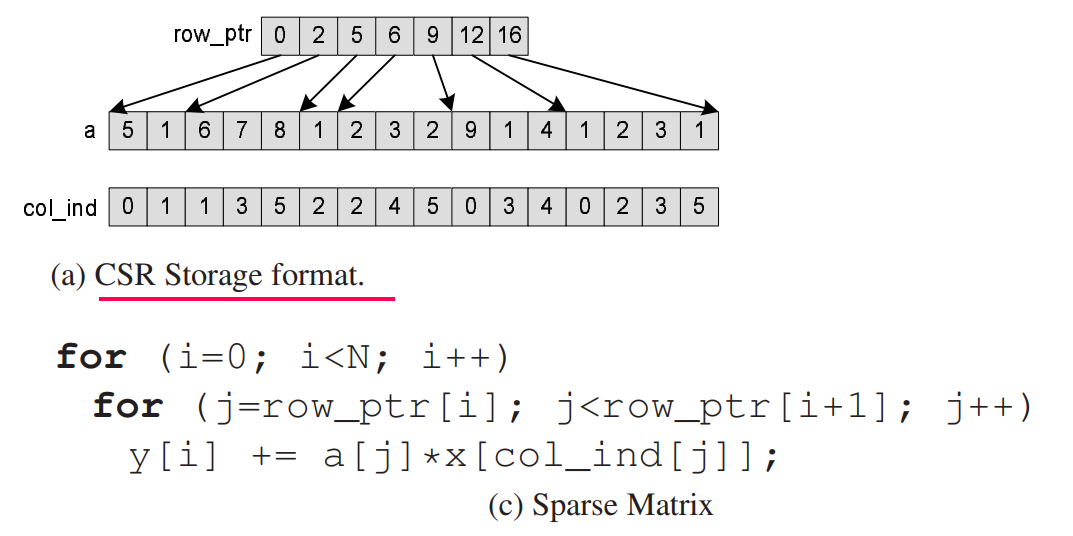
CSR: Compressed Sparse Row format
- stores matrix in 3 lists
- “row list” for each row contains a number that is references a position in the value and column lists, where the row’s column and values start
- “column list” contains column indexes and is indexed by the row list
- “value list” contains values and is indexed by the row list
- to access a row
iretrieveindexes = range(row_list[i], row_list[i+1]), then build row’s list of list representationrow_lol = [(i, column_list[j], value_list[j]) for j in indexes] - fast matrix to vector multiplication (product) thus useful for KNN
- fast CSR + CSR, CSR * CSR, CSR * Dense
- fast row slicing
- slow transpose
- converting to Scipy’s CSR with
tocsrmethod
CSC: Compressed Sparse Column format
- similar to CSR except columns and rows switch their role
Other formats
Block Sparse Row format, Diagonal, …
How to Use Sparse Matrices
You can use Scipy library for sparce matrixes. The main image is from this study.

