
Have you forgotten about Transformer’s feed-forward layer? It eats 2/3 of the model params! Feed-forward layer is sometimes also called MLP layer.
The last post on LambdaNetwork sketches self-attention as a differentiable query of a key-value store. The Transformer’s feed-forward sublayer is similar to the cross-attention attending to a separate sequence via key and value input. So, it is a bit like differentiable key-value memory.
Can we gain more understanding of Transformer model operation by looking at the feed-forward layer?
Where is Feed-Forward Layer?
Where is Feed-Forward layer within the architecture exactly? Feed-forward layer camps within encoder and decoder layers as a sublayer just behind the self-attention sub-layer.

What is Feed-Forward Layer?
-
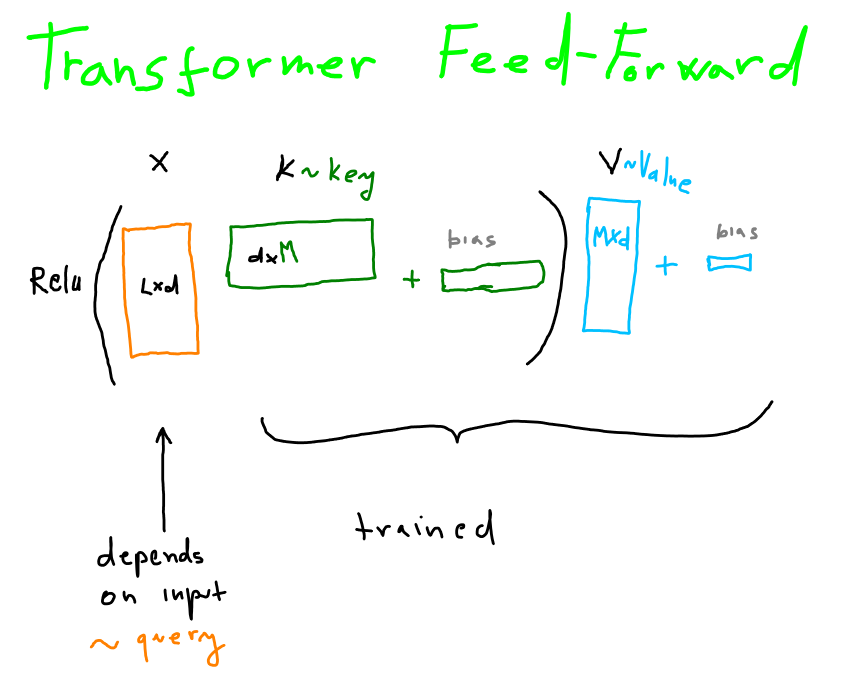
It is a position-wise transformation that consists of linear transformation, ReLU, and another linear transformation.
-
formula: \( \mathrm{ffLayer} = \sum_i \mathrm{relu}(q_i k_i^\intercal + b_i) v_i + c\)
-
Don’t forget the residual connections and their addition and normalization to outputs of both feed-forward and self-attention.
Feed-Forward Layer vs Cross-Attention
Have you noticed that the feed-forward sublayer is akin to key-value memory of the self-attention except for non-linearity is ReLU and bias-terms \( b, c \)?
\( \mathrm{keyValMemory} = \sum_i \mathrm{softmax}(q_i k_i^\intercal) v \)
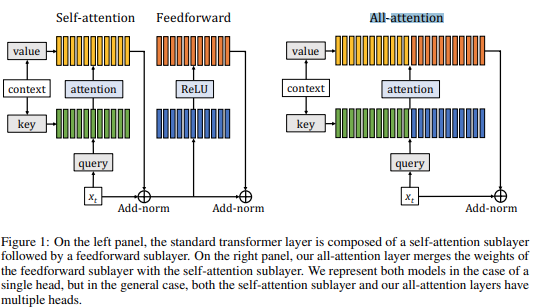
More specifically feed-forward layer is a bit like a cross-attention with a trainable embedding sequence. Augmenting Self-attention with Persistent Memory paper saw the similarity of feed-forward sublayer and self-attention and suggested an architecture simplification. They restated the feed-forward layer, incorporated it into the self-attention sublayer, and named the new block “All-attention”. And they reportedly slightly outperformed the vanilla model on the next token prediction task.
Google’s PaLM model authors adopted gated linear unit (GLU) based modification to their feed-forward layer, which is mildly similar to cross-attention:
SwiGLU Modified Feed-Forward Layer
- instead of RELU \( max(0, xW_1 + b_1)W_2 + b_2 \) uses SwiGLU \( (\mathrm{Swish}(xW_1) \otimes xV ) W_2 \)
- gated linear unit (GLU) is a sigmoid controlled output
- midly similar to cross-attention with a static sequence
- ~1% higher accuracy in compute equivalent setup
- swish activation: \( \mathrm{Swish}(x) := x (1 + exp(−x))^{−1} \)
- used in PaLM model
Feed-Forward vs Softmax Linear Unit (SoLU)
- the definition is \( x * \mathrm{softmax}(x) \)
- SoLU uses Softmax instead of the ReLU
- SoLU reminds a gating mechanism similar to SwiGLU
- SoLU learns more interpretable memories, the same metrics and speed (Layer norm not needed.)
But does the feed-forward sublayer really behave like key-value memory not only talk a talk?
Feed-Forward Key-Value Memories - Empirical Study
In Transformer Feed-Forward Layers Are Key-Value Memories authors show that feed-forward layer does walk the walk of a key-value store.
The paper studies activation of feed-forward keys for the last position of the input sequence. The activated keys are keys with top-n ReLU outputs for given feed-forward sublayer. For most of the keys in the feed-forward sublayers the authors found one or more human-interpretable input text patterns for which the key in feed-forward was being activated. Text patterns ranged from simple exact word matches (e.g. last word is “substitutes”) to more complex topics (e.g. “one of”, “part of”, “among”). Authors also observed that the upper layers memorize more abstract patterns.
Unfortunately not all samples are provided in the pre-print. Furthermore, they report they found more than one pattern per key. Were those patterns referencing a single topic or disparate topics? If single key was associated with multiple topics, can we still look at it as a memory cell?
Activated feed-forward values predicted model’s next output tokens in higher layers only, but not in lower layers. Typical example activated tens of memories which were then aggregated (non-zero coef mems). The model output vector differed from all single memory predictions (single value vectors) 68% of the time. Remaining 32% are perhaps stop words and a like. The feed-forward residual connections predicted next output token increasingly in the higher layers. Could be that the internal embedding space is changes between layers? Is the model refining its prediction from layer to layer?
They additionally observed that top-1 predictions of sublayer residuals mostly not match feed-forward. These sublayer-outputs seem to not agree but rather compose. Does feed-forward dampen or “veto” residual vectors towards other candidates? In 66% adding feed-forward to residuals changed prediction is to a semantically unrelated word. Is this used by the model for predicted sequence re-arrangements?
ROME method Feed-Forward Layers as Editable Memories
The ROME paper develops a technique for locating memories and associative rules in GPT transformer for specific facts ,e.g. Eiffel tower is in Paris. Additionally, they introduce a technique for editing these memories without rest of the model.
Mixtral Sparse Mixture-of-Experts
In 2023, sparse representations also appeared in practise in the Sparse Mixture-of-Experts deep-learning architecture exemplified by widely-used Mixtral model. In each feed-forward layer of Mixtral model, only 2 of 8 (25%) get activated during inference.
Mixtral is a sparse mixture-of-experts network. It is a decoder-only model where the feedforward block picks from a set of 8 distinct groups of parameters. At every layer, for every token, a router network chooses two of these groups (the “experts”) to process the token and combine their output additively.
LambdaNet Positional Embeddings vs Feed-Forward Layer
LambdaNet layer positional embeddings are something between self-attention and feed-forward layer in transformer, but neither. They are about querying pattern-values store. The keys are constants like in feed-forward, but queries and values are derived from the input. Whereas in the feed-forward the values are constants as well.
Meet Other ML Enthusiasts One-on-One Online
Video-call each week an interesting person and break out of your remote isolation. Network One-on-One Around Your Online Village with RandomMeets.

