
- Tokenization is cutting input data into parts (symbols) that can be mapped (embedded) into a vector space.
- For example, input text is split into frequent words e.g. transformer tokenization.
- Sometimes we append special tokens to the sequence e.g. class token ([CLS]) used for classification embedding in BERT transformer.
- Tokens are mapped to vectors (embedded, represented), which are passed into neural neural networks.
- Token sequence position itself is often vectorized and added to the word embeddings (positional encodings).
Tokenization in NLP
- Input data text is split using a dictionary into character chunks called tokens
- The vocabulary contains around 100k most common sequences from the training text.
- Tokens often correspond to words of 4 characters long with prepended whitespace or special characters.
- common tokenization algorithms are BPE, WordPiece, SentencePiece
- Text tokens can be converted back to text, but sometimes there is a loss of information.
- Tokenization in NLP is a form of compression - dictionary coding.

Is NLP Tokenization Slow?
Does tokenization take up resources?
Tokenization is low resource CPU operation. It is a much lower resource intensive than the model inference, which on contrary is performed on the GPU and involves large matrix multiplications. Tokenization can be around 1% of the BERT model inference time.
Tokenization is mostly splitting text on space characters and sometimes further using a dictionary lookup. For example, tiktoken library can process (throughput) Mega Bytes per second of text with a single CPU core.
Tokenization In Continuous Modalities Vision or Speech
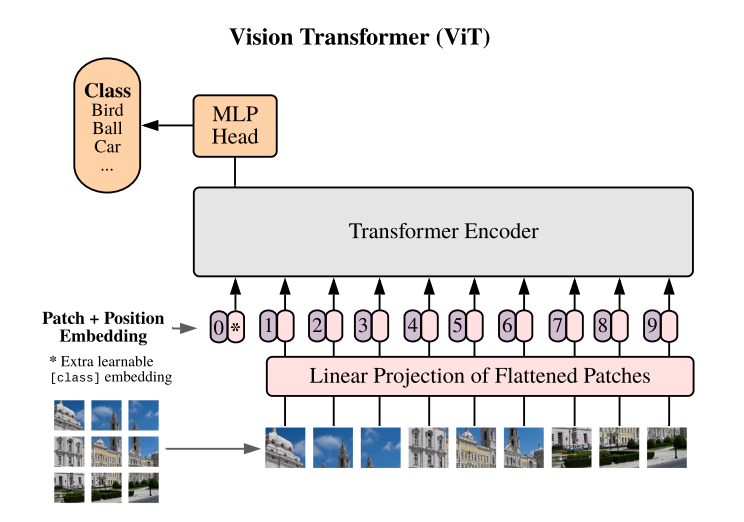
- Tokenizers are not quite present in modalities like image or speech.
- Instead, the images or audio is split into a matrix of patches without dictionary equivalent as in case of the text.
- Image architectures Vision Transformer (ViT), Resnets split image into overlapping patches and then encode these.
- Outputs embeddings of these can then be passed to ,e.g., transformer (CMA-CLIP or MMBT)
Quantization
- related to tokenization in that it outputs finite number of items from a dictionary
- is used in Wav2vec and DALL-E 1 and VQ-VAE
- replaces the input vector with the closest vector from a finite dictionary of vectors called codebook
- during training, backward pass uses Gumbal softmax over the codebook to propagate gradient
- product quantization: concatenation of several quantizations then linear transformation
The Most Common Tokenizers in NLP
A list of commonly used tokenizers sorted by their date of introduction.
FastText Tokenizer
- Older models like Word2vec, or FastText used simple tokenizers, that after some preprocessing simply split the text on whitespace characters. These chunks are often words of a natural language.
- Then, if the character sequence chunk is present in a dictionary of most common chunks, and return an index in the dictionary.
- If not found, most tokenizers before FastText returned a special token called the unknown token. FastText solved this problem by additional split on the word level into fixed size “subwords”, but to find out more details about FastText read this post.
- BPE never returns unknown token, and instead composes the out-of-vocab words from parts up to individual characters.
BPE Tokenizer
Byte-Pair-Encoding (BPE) algorithm:
- BPE pre-tokenizes text by splitting on spaces
- start with only characters as token
- merge the highest frequency token pair from the text
- stop if max vocabulary size reached, otherwise loop to previous step
WordPiece vs BPE Tokenizer
- WordPiece merges token pair with highest
count(ab) / count(a)count(b) - Used for BERT, DistilBERT, Electra
Unigram Tokenizer
- Unigram construction instead of merging and adding to a vocabulary like BPE, it removes tokens
- A vocabulary loss is constructed as expectation maximization loss summing over all tokenizations of all corpus’ subsequences.
- The probability of each token is approximated as independent of other tokens.
- Starts with a very large vocabulary and removes fixed number symbols such that the vocabulary loss increase minimally
- Stop if vocabulary size reached, otherwise loop to previous step
SentencePiece vs WordPiece Tokenizer
- Japanese, Korean, or Chinese languages don’t separate words with a space
- SentencePiece removes pre-tokenization (splitting on spaces)
- instead tokenizes text stream with usually with Unigram or alternatively with BPE
- T5, ALBERT, XLNet, MarianMT use SentencePiece with Unigram

