
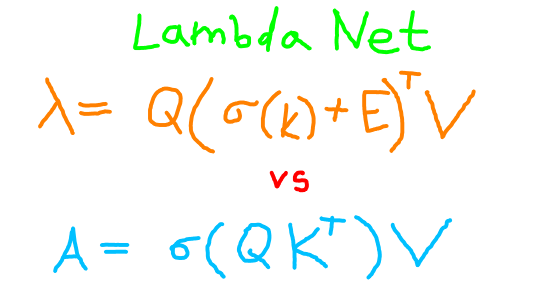
Lambda Network head achieved SoTA, when sewed on decapitated Resnet50, outperforming EfficientNet on ImageNet. LambdaResNet also achieves ~4.5x speedup over EfficientNet at same accuracy.

LambdaResNet however suffers from time-space complexity of sequence size squared and Relu-Performer could overtake it future.
The majority of model’s performance comes from translation-invariant positional embeddings. The positional embeddings are used similarly to a key matrix in a self-attention. But there is no softmax function used. Then the embeddings are trained, but are independent of the inputs (static). And every output position has a separate key.
If self-attention is differentiable querying of a key-value store, then LambdaNet is differentiable querying of a pattern-value store, where the patterns are positional embeddings.
How similar are Lambda Interactions to Self-Attention?
Are there any similarities between Lambda Networks Interactions and Transformer or Performer attention? Your thirst for knowledge will be satisfied here, friend!
In following \( X \) will denote input sequence of dimension \( n \times d \), where \( d \) is the token embedding dimension and \( n \) is the sequence length. The interaction and attention context is the entire input sequence \( X \) for simplicity. But for experiments with images the authors needed to limit the attention to image patches of 23x23 pixels.
Lambda Networks Interaction
Given a query \( Q = (W_Q X) \in \mathbb{R}^{n \times k} \),
a query vector \( Q_l = Q_{l, \cdot} \),
a key \( K = (W_K X) \in \mathbb{R}^{n \times k} \),
and a value \( V = (W_V X) \in \mathbb{R}^{n \times d} \).
Positional embeddings are denoted by \( E \in \mathbf{R}^{n \times n \times k} \). For each two positions in the input sequence there is an embedding vector. Translational invariance \( E_{i, j} = E_{t(i), t(j)}\) is enforced by storing the embeddings in translation-invariant (relative) format.
Softmax applied along the dimension \( n \) is denoted by \( \sigma \). The softmax serves here to strongly prefer select few of the value vectors indexed by \( n \). However the selection factor (the logit) here is not the query-key match (dot product). But rather to the key vector itself. That may be the reason, why presence of \( \sigma(K) \) does not provide much performance gain (See the performance section).
In the paper the lambda layer is defined in a very unfamiliar form. The left side of the equation below serves as a reference to the original paper. On the left you can see a linear function \( \lambda \) parametrized by \( l \) projecting a query vector. The resulting vector is transposed, such that the right side reminds you an self-attention vector.
\( \forall l \in \lbrace 1, …, n \rbrace\),
\( (\lambda_l Q_l)^\intercal = Q_l \odot_k (\sigma(K) + E_l )^{\intercal} \odot_n V \)
The matrix multiplication subscript in above declares along which dimension it operates. Notice that in contrast to self-attention each output position \( l \) has a different key \( \sigma(K) + E_l \) applied to the query, because positional encodings matrix is 3 dimensional (a cubic matrix). Each query vector \( Q_l \in \mathbb{R}^{k} \) gets its own special key \( E_l^\intercal \in \mathbb{R}^{k \times n} \).

I will omit the index \( l\) to obtain a format akin to self-attention.
\( \mathrm{lambdaLayer} = Q (\sigma(K) + E)^\intercal V \).
Note that the paper also mentions additional dimension called “intra-dimension” \( u \), which I set to 1 as it is not important. LambdaNet’s authors apparently just love multi-dimensionality.
Transformer Self-Attention
Normalized softmax along dimension \( n \) is denoted by \( \sigma \). Transformer positional encoding is denoted by \( P \in \mathbf{R}^{n \times d} \). The positional embeddings are learned e.g. in case of BERT transformer model.
Given a query \( Q = W_Q (X + P) \in \mathbb{R}^{n \times d}\),
a key \( K = W_K (X + P) \in \mathbb{R}^{n \times d}\),
and a value \( V = W_V (X + P) \in \mathbb{R}^{n \times d}\).
Self-attention is defined as:
\( \mathrm{selfAttention} = \sigma(QK^\intercal) V \)
Performer Self-Attention Approximation
Kernel function approximating softmax via a feature function \( \phi \in \mathbb{R}^{n \times d} \rightarrow \mathbb{R}^{n \times k} \), which maps to the smaller dimension \( k \).
The Peformer self-attention approximation is defined as:
\( \mathrm{performerAttention} = \phi(Q) \phi(K)^\intercal V \)
How Is LambdaNet Doing in Space and Time Complexity?
The worst in terms of complexity is vanilla transformer self-attention. For each batch item it requires \( n^2 \) time and space, because it materializes attention matrix for each batch input.
The second place takes the Lambda Layer. For entire batch it requires only \( n^2 \) time and space. The savings come from positional embeddings having \( n^2 \) time and space size, but being the same for entire batch.
The first places takes the Performer. The Performer’s time and space complexity is linear in both batch size and sequence length \( n \). Additional time speed up in Performer comes from replacing the exponential with Relu in the kernel softmax approximation.
How Lambda Layer Performs Compared to Self-Attention and Performer?
The paper compares Lambda layer to Transformer self-attention. While Lambda layer out-performs self-attention, it does so by only a small margin. For experimental specifics, please see the paper. Note that in the experiment the lambda layer is not applied to the entire picture, but rather to a small neighborhood of each pixel due to time and space complexity.

Comparison of the Relu-Performer and Lambda Network is not available as of 2020-11-30. I think Relu-Peformer will likely outperform Lambda layer, although it needs to be tested first.
Are Lambda’s Positional Embeddings Required?
Could we possibly get rid of the positional embeddings, if they consume so much? No, they drive most of the performance. That is at least in case of the image classification task.

If you remove the “content” part \( \sigma(K) \), that does not contribute much accuracy, the lambda layer becomes: \( Q E^\intercal V \).
Meet Other ML Enthusiasts One-on-One Online
Video-call each week an interesting person and break out of your remote isolation. Network One-on-One Around Your Online Village with RandomMeets.

