The presentation explains the development of large language models like ChatGPT, which can generate text by predicting input text continuation. The idea of a talking machine has been around since the 1700s, but it wasn’t until the development of powerful computers and computer science that it became a reality. Simple document representations, such as counting word occurrences, were used to create sparse matrices as feature vectors in methods like term frequency–inverse document frequency and latent semantic analysis. Non-contextual word vectors were created using word2vec, which trained embeddings to sum up close to the middle word vector. Later, contextual word vectors were created using transformer architecture, which consumes the entire input sequence and is state-of-the-art in 2022.
Dream of a Talking Machine
- Idea of a talking machine since 1700s, but weak computers and computer science
- ChatGPT does almost what was predicted, but how?
- How to instruct large language model to perform tasks?
- How represent knowledge in computers?
- How to generate the answers?
by his contrivance, the most ignorant person, at a reasonable charge, and with a little bodily labour, might write books in philosophy, poetry, politics, laws, mathematics, and theology, without the least assistance from genius or study. ... to read the several lines softly, as they appeared upon the frame (Gulliver's Travels, by Jonathan Swift 1726, making fun of Ramon Llull 1232)
Text Prompt as an Interface
- For example 2001: A Space Odyssey HAL 9000
- input textual instructions e.g. explain a riddle
- based on its knowledge computer generates the answer text

Simple Document Representations
- Once were paper archives replaced with databases of textual documents some tasks became cheaper: search by list of words (query) ~1970s, finding document topics ~1980
- simplest methods: counting word occurrences on documents level into sparce matrices as feature vectors in methods term frequency–inverse document frequency (TF-IDF), Latent semantic analysis (LSA)
- this co-occurrence of words in documents later used to embed words

Non-Contextual Words Vectors
- document split into sentence sized running window of 10 words
- each of 10k sparsely coded vocabulary words is mapped to a vector (embedded) into a 300 dimensional space
- the embeddings are compressed as only 300 dimensions much less than 10k vocabulary feature vectors
- the embeddings are dense as the vector norm is not allowed to grow too large
- these word vectors are non-contextual (global), so we cannot disambiguate fruit (flowering) from fruit (food)
Word2vec Method for Non-contextual Word Vectors
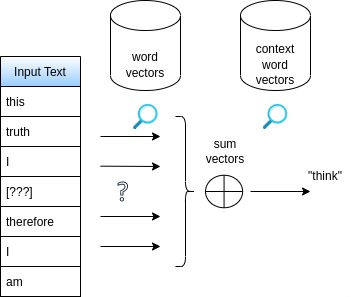
- Word2vec (Mikolov 2013) trains the middle-word vector to be close to sum of 10 surrounding words embeddings.
- Even simpler method is GloVe (Pennington 2014), which counts co-occurrences in a 10 word window, then reduces dimensionality with SVD.
- Other similar methods are FastText, StarSpace.
- Words appearing in similar contexts have similar Word2vec embedding vectors. Word meaning disambiguation is not possible.
- Vector manipulation leads to meaning manipulation, e.g., vector operation
v(king) – v(man) + v(woman)returns a vector close tov(queen).
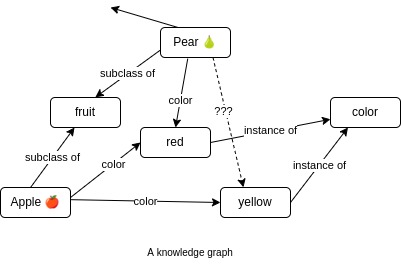
Knowledge Graph’s Nodes Are Disambiguated
- knowledge graph (KG) e.g. Wikidata: each node is specific fruit (flowering) vs fruit (food)
- KG is a tradeoff between database and training data samples
- Wikipedia and the internet are something between knowledge graph and set of documents
- random walks over KG are valid “sentences”, which can be used to train node embeddings e.g. with Word2vec (see “link prediction”)
Contextual Word Vectors with Transformer
- imagine there is a node for each specific meaning of each word in hypothetical knowledge graph
- given a word in a text of 100s of words, the specific surrounding words locate our position within the knowledge graph, and identify the word’s meaning
- two popular model architectures incorporate context:
- recurrent neural networks (LSTM, GRU) are sequential models with memory units
- transformer architecture consumes the entire input sequence is State-of-the-art 2022
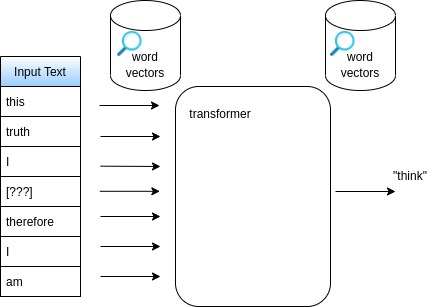
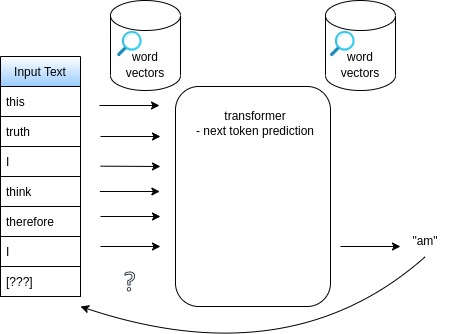
Large Language Models
- generate by predicting input text continuation
- $10M transformers trained on large amount of text from the internet in 2022
- can solve wide variety of problems like explaining jokes, sometimes with human level performance
- examples: PaLM (2022), RETRO (2021), hybrids with algorithms
- ChatGPT additionally trained to chat using RLHF alignment method
Future: Hybridizing Text with Algorithms
- ChatGPT and other Large Language Models hallucinate despite alignment with RLHF
- If neural network has a intuition, what is repetition, search, self-reflection?
- Read more about reasoning without hallucinations hybridizing neural networks with code
- Also: understanding image and text regardless of a language

Instructing ChatGPT and Large Language Models
- Prompting is asking the LLMs right questions
- Common prompting techniques: being specific, provide examples, allow thinking step by step, self-reflecting
- Use cases: question answering, coding, form filling, data schema extraction, knowledge graph construction